


(© Konbini)
À voir aussi sur Konbini
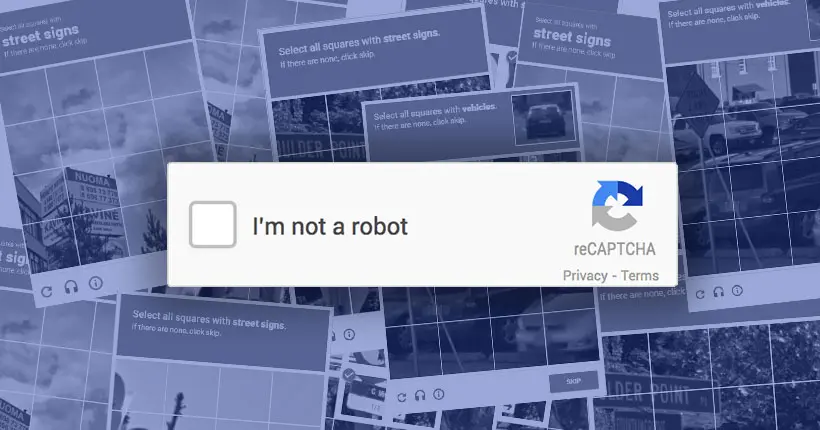
C’est probablement LA case de formulaire la plus énervante au monde, celle où l’on doit cocher “Je ne suis pas un robot” alors que l’on pensait avoir fini de tout remplir. reCAPTCHA après reCAPTCHA, l’internaute qui n’avait rien demandé est sommé de reconnaître des devantures de magasins, des voitures ou des feux de signalisation. Étape obligatoire d’autant plus pénible que dans certains cas, un bout d’image dépasse sur la case d’à côté, et on ne sait plus s’il faut cliquer, au risque d’être pris pour un robot et de se taper des angoisses existentielles à la Philip K. Dick.
Avant le reCAPTCHA
D’abord, un point de généalogie. Le reCAPTCHA est le descendant direct du simple et générique CAPTCHA, un petit test quasiment disparu qui se trouvait à la fin de beaucoup de formulaires. La plupart du temps, il s’agissait de lettre déformées que, théoriquement, seuls les humains pouvaient recopier sans fautes, contrairement aux innombrables bots qui parcourent le web et cherchent à entrer un peu où ils veulent, à des fins souvent malveillantes.
L’acronyme de CAPTACHA, Completely Automated Public Turing test to tell Computers and Humans Apart ne dit pas autre chose : il fait référence au fameux test de Turing, qui édicte les conditions pour qu’une machine puisse se faire passer pour un humain.

Un CAPTCHA de 2005 © Martin/Wikipedia
D’après Wikipedia, le terme a été inventé en 2003, par trois informaticiens de l’Université de Carnegie-Mellon, aux États-Unis. Des dispositifs antérieurs au CAPTCHA avaient déjà été mises en place sur certaines plateformes, mais le procédé n’était pas aussi harmonisé. Le CAPTCHA a connu son heure de gloire. Mais parallèlement, les techniques de reconnaissance de caractère (OCR) se sont perfectionnées. Les bots ont rattrapé les humains. Les reCAPTCHA fonctionnant sur des technologies différentes ont donc progressivement pris le relais. Darwin aurait adoré.
Numériser le New York Times
Mais comme rien n’est simple, le reCAPTCHA relou que l’on connaît aujourd’hui est très différent du reCAPTCHA version 1. Encore un peu de généalogie s’impose, déso.
Le reCAPTCHA V1 ressemblait à s’y méprendre au CAPTCHA traditionnel : il fallait déchiffrer un texte un peu difficile. Sauf que, pour la première fois, on s’est dit que si l’internaute devait se creuser la cervelle, autant que ça serve à quelque chose. Le reCAPTCHA V1 a donc servi, dans ses débuts, à déchiffrer des archives numérisées illisibles du New York Times, comme le raconte… le New York Times.
Ce reCAPTCHA V1 était composé de deux textes, l’un issu de l’archive numérisée indéchiffrée, l’autre était un texte déjà connu de la machine, servant de vérification. En recoupant les contributions de milliers, voire millions d’utilisateurs, l’ordinateur parvenait à déchiffrer l’archive indéchiffrable.
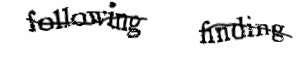
Un ReCAPTCHA de 2007 (© BMaurer/ Wikipedia)
Cette idée brillante, nous la devons à Luis von Ahn, qui a sorti son reCAPTCHA V1 en 2007. Ce chercheur en informatique d’origine guatémaltèque est devenu célèbre dans le monde de la tech pour avoir créé, par la suite, l’une des plus applis les plus successful d’apprentissage de langues étrangère, Duolingo.

Luis von Ahn (© EneasMx/Wikimedia)
L’immixtion de Google
Google flaire le bon coup et rachète la technologie de von Ahn en 2009 pour un montant tenu secret. Comme on ne change pas une recette qui gagne, les internautes restent mis à contribution. Sauf qu’ils déchiffrent, en plus, l’immense bibliothèque d’ouvrages numérisés qu’est Google Books. Si bien qu’en 2011, les 13 millions d’articles du New York Times et Google Books dans son ensemble sont entièrement lisibles.
Puis reCAPTCHA évolue. Entre la V1 et la version d’aujourd’hui, la chronologie n’est pas simple à retracer, mais on est sûr d’une chose : on s’éloigne complètement du CAPTCHA traditionnel avec ses lettres qui donnent le tournis. Deux nouveaux types de reCAPTCHA, qui cohabitent sur Internet, surgissent.
Google invente d’abord le reCAPTCHA “behavioriste”, le noCAPTCHA. Révolutionnaire, il analyse le comportement du visiteur sur la page. Si la recette est secrète, on sait tout au plus que le noCAPTCHA prend en compte, parmi plusieurs indicateurs, les mouvements de la souris sur la page.
Si le noCAPTCHA estime que le visiteur est humain, alors il suffit simplement de cliquer sur la case “Je ne suis pas un robot“, sans autre forme de test. La belle vie pour l’utilisateur, en somme. Dans la foulée, Google arrive même à inventer un reCAPTCHA totalement invisible : seulement, et seulement si l’humain a un comportement bizarre sur la page qui laisse penser qu’il s’agit d’un bot, alors le cadre apparaît.
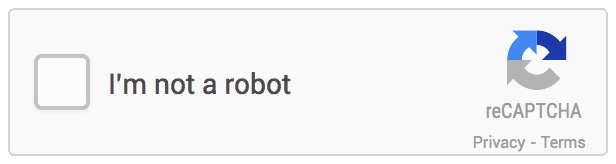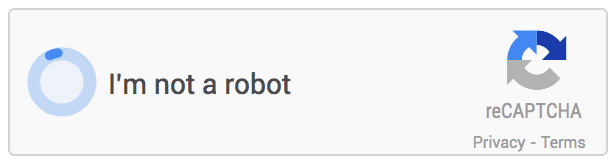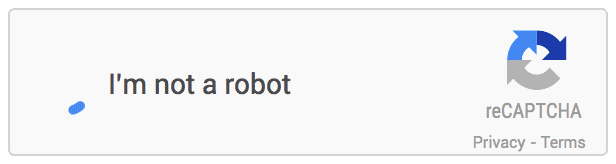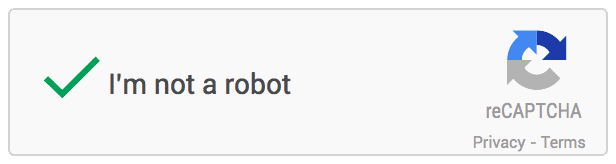
Le ReCAPTCHA ultra simple de Google où il suffisait de cliquer sur la case.
reCAPTCHA et le “digital labor“
Parallèlement au noCAPTCHA, le reCAPTCHA prend une autre direction. Toujours dans l’idée de faire bosser les internautes, Google décide d’utiliser le temps de clic disponible pour une toute autre chose que Google Books : faire progresser le “machine learning“, la fameuse intelligence artificielle convoitée par les géants du Web et les États.
Lorsque des millions d’internautes identifient des images de feux de circulation ou de voiture, ils créent des immenses jeux de données labellisés, autrement dit des images étiquetées, indiquant ce qu’elles représentent. Ces énormes datasets serviront, par la suite, à éduquer les algorithmes de “machine learning“.
À quoi et à qui servent ces datasets ? Google, sur son site web, ne nous éclaire pas beaucoup :
“reCAPTCHA fait une utilisation positive de cet effort humain. Le temps utilisé pour la résolution permet de numériser du texte, annoter des images, construire des datasets de machine learning. En retour, cela contribue à préserver les livres, améliorer les cartes et résoudre des problèmes difficiles dans le domaine de l’IA.”
Étant donné que la plupart des images sont prises dans la rue et semblent provenir de Google Street View, il est fort possible que cela serve à améliorer la reconnaissance d’objets dans Google Maps. La reconnaissance d’éléments urbains pourrait surtout être très utile pour les voitures autonomes que le futur nous promet.
Google partage-t-il ses datasets avec la concurrence (ce qui n’aurait rien d’incongru, puisque beaucoup de datasets d’origine privée, ceux de Google compris, deviennent publics pour créer une émulation générale) ? Nous avons contacté le service de presse de l’entreprise, qui n’est pour l’heure toujours pas revenu vers nous.
Partage ou pas partage, impossible ici de ne pas penser au terme de “digital labor” forgé par le sociologue Antonio Casilli, récemment interviewé par Konbini :
“Pendant que nous travaillons gratuitement, en Occident comme dans les pays du Sud, des millions de “micro-tâcherons” louent leurs services pour cliquer, étiqueter, labelliser ou modérer contre quelques centimes.”
Bots vs humains, la guerre continue
Si les reCAPTCHA sont devenus aussi relous et difficiles, ce n’est donc pas uniquement pour les beaux yeux de Google. Avec la progression du “machine learning”, de l’IA, les bots sont de plus en plus forts et l’histoire ne cesse de se répéter. Interrogé par “The Verge”, l’ingénieur en chef des reCAPTCHA, Aaron Malenfant, indique que d’ici 5-10 ans, il sera extrêmement difficile voire impossible d’imaginer des CAPTCHA que les machines ne pourront décoder, même si l’on envisage des mini-jeux vidéo de vérification ou des devinettes évoluées.
À quoi ressemblera le CAPTCHA du futur ? Un bout de réponse nous est peut-être fourni avec la dernière version du reCAPTCHA, la V3, lancée par Google en octobre dernier. Le webmaster installe un script sur toutes ses pages, et dispose ensuite d’un méga tableau de bord où chacune des pages reçoit un “score” mesurant la proportion bots/humains. Si les bots sont nombreux, bim, mauvaise note, et vice-versa.
En plus des ingrédients behavioriste, le reCAPTCHA V3 analyse des cookies du navigateur ou encore des modèles de navigation. Si, et seulement si la page semble majoritaire visitée par des bots, alors le webmaster peut décider de mesures radicales, bien plus que l’étiquetage d’images, comme l’envoi d’un SMS de confirmation. Autant de données envoyées qui donneront du grain à moudre à l’ogre Google.
Et si Google est bel et bien devenu hégémonique sur le territoire des CAPTCHA, des concurrents, qui se présentent davantage comme des détecteurs de bots que des développeurs de CAPTCHA, à l’instar de Human Presence ou Shape (créé par un ancien de Google), cherchent à grignoter des parts de ce marché jonché de bots sans pitié.







